Goals
In my first semantic segmentation project, I used simulator data to train a neural network that can label which pixels are cars vs roads. The simulator data wasn’t noisy, the cars and roads took up a significant part of the image, and the ground truth labels were very precise. Real world images are anything but clean.
I had an opportunity to revisit semantic segmentation with real world images when Airbus challenged Kagglers to locate ships in satellite imagery as fast as possible.
Labeling satellite images is one of the best applications of semantic segmentation.
Use cases include:
Labeling roads, houses, buildings:

Remote sensing for agriculture, land management, and construction.

In this challenge, Airbus provides satellite images and expects Kagglers to find ships that range from tiny boats (only a few pixels wide) to large freight carriers.
Expected results (top row is input and bottom is the expected output):

The yellow blobs indicate where the ships are.
Data Exploration
The competition uses ~ 30 GB of square images 768x768 each.
Ship vs No Ship
Most (65%) of the training images do not contain any ships at all.
Samples of no ship images:

Knowing this, I can see if the test set has a similar distribution of ships/non-ships as the training set. If the test set is different, I’ll need to modify the training set to be more representative of the test set.
Since I don’t have the masks for the test set, I can submit a blank (no ships) prediction for all images in the test set and deduce the percentage of non-ships images from the score. The test set seems to be mainly made up of non-ship images as well.
Many images with ships only contain 1 ship.

Sample of images with 1 ship:

Sample of images with 1-5 ships:

Sample of images with 6+ ships:
Some of these ships are tiny, can you spot these ships in the far right image above?
What if I zoom in more?

Even at this zoom, some of the ships are indistinguishable from rocks.
Some of the images can contain partial ships in any orientation.

This means that data augmentation in terms of rotations and flips will help make the model more robust to images at all camera orientations.
Take a look at the last row of images. Notice anything odd? The ground truth masks provided in the training set seem to be machine generated bounding boxes instead of human-labeled masks of the ships. The ship in the last picture has a pointed, triangular bow but the mask just shows a rectangle. This means that there is an opportunity to use a detector for rotated bounding boxes to complement the semantic segmentation detector.
Next let’s look at the ship sizes in the training set:

The smallest ship is just 2 pixels, out of 589824 pixels for the entire image (768x768)!
See my dataset exploration code here.
Scoring
The competition is judge using an F2 score over different intersection over union (IoU) thresholds.
In layman’s terms, the evaluator compares the predicted ships vs the ground truth ships at different overlaps, ranging from 50% to 95% overlap in 5% increments. For example at 50%, ships that have a minimum overlap of 50% with the true positions will count as a hit.
Then the results from all the thresholds are averaged for an image. Averages from images are summed to give a total score.
The F2 scoring will favor recall over precision.
Approach
My initial approach was to train a U-Net model on the full dataset. U-Net architectures use a encoder-decoder architecture where the encoder breaks the image down into a series of features and patterns (such as lines, faces, etc) and the decoder takes the features and maps them to specific pixels that exhibit the desired shapes (ships in our case).
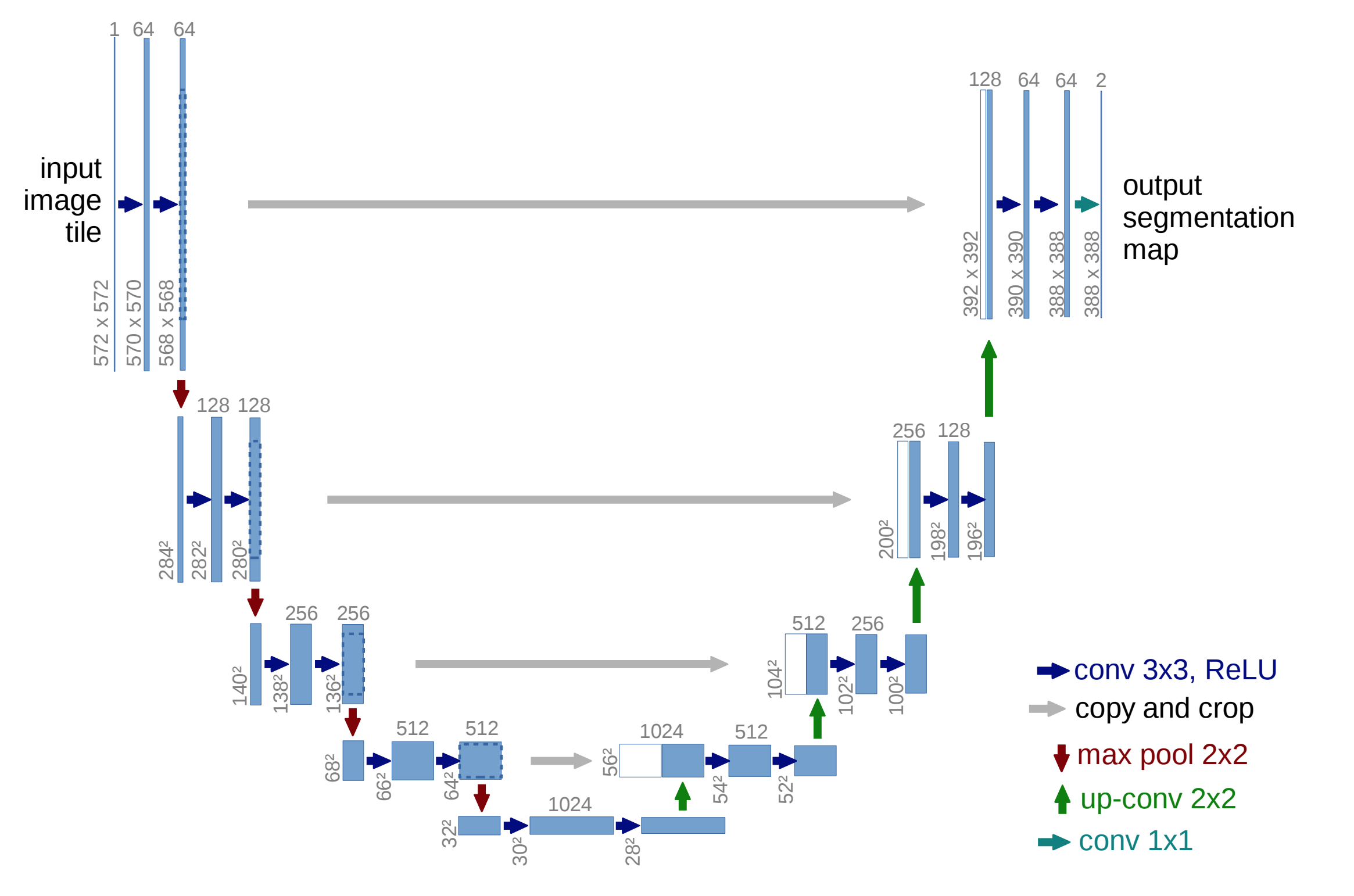
U-Net accepts any feature extractor as its encoder. The feature extractors used most often are the “battle-tested” neural networks that have performed well at image classification, such as ResNets and InceptionNets. The heavier the network used as the encoder, the slower the U-Net is to train.
To start, I used the relatively light custom U-Net. I then moved to using ResNet18, ResNet34 and DenseNet121 as encoders.
Iafoss (who would later be my teammate) showed everyone a better way than just training on the full dataset.
He showed that since most of the images have no ships and one of the goals of the competition is to detect ships as fast as possible, we can train a image classifier to determine whether an image has a ship or not very quickly and accurately before trying to pinpoint the ships in the image. He used transfer learning with a ResNet34 architecture to quickly train a ship-no-ship classifier that is 98% accurate. See his code here.
Iafoss didn’t stop there. He followed that up with an amazing example of using a U-Net with a ResNet34 encoder. In the example, he also showed how to use test time augmentation to improve the score. See his code here. Iafoss was definitely the MVP of this competition.
To summarize his approach:
- Given an image, detect whether there is a ship
- If there is a ship, feed it into the U-Net to determine which pixels represent ships and which are not
- Transform the image (flips, rotations) and feed it through U-Net again, then average the results for that image to get a rotation-invariant result
- Split the masks up into individual instances of ships
I started with Iafoss’s approach as a baseline. Then I explored how I can add post-processing to the prediction masks to boost my score on the public LB.
My first instinct was to act on the fact that the ship masks in the training set looked more like rotated bounding boxes instead of hulls of ships. From this realization, I could:
- Train a new network to output rotated bounding boxes instead of pixels, then fill in those boxes
- Apply bounding box estimation to blobs predicted by the existing U-Net segmentation network
I chose the second path because it was a faster way of seeing how boxes affect scores.
Here’s how I’m approximating the bounding box of a blob using OpenCV.
def find_bbox(mask):
canvas = np.zeros((768,768,3))
_, cnts, hierarchy = cv2.findContours((255*mask).astype('uint8'), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for cnt in cnts:
rect = cv2.minAreaRect(cnt)
box = cv2.boxPoints(rect)
box = np.int0(box)
cv2.fillPoly(canvas, [box], (255,0,0))
red = canvas[:,:,0]
return (red/255)
After applying the bounding box post processing, my score improved in the local validation set but dropped in the test set. This is my first suspicion that the ground truth for the test set might be different than that of the training / validation set.
Next I spent some time toying with different thresholds for what constitutes a ship in terms of prediction confidence and ship sizes. Through trial-and-error and later grid search, I found that a simple post-processing method of using the right thresholds to exclude ships that are too small or too fuzzy to tell led to the highest score. I was able to get a score of 0.743, which puts me in the top 10 with about two weeks to go.
Right around this time, I noticed that iafoss had just teamed up with Trian, a Kaggle master. I had never worked on a team before and wanted to learn as much as possible, so I asked to join their team. I wanted to trade GPU hours and grunt work for knowledge.
Teamwork
After iafoss and Trian accepted me into their team, we got to work making ensembles of our respective models. An ensemble typically takes predictions from multiple models, trained in many different ways and average them together to make more robust predictions.
The models we used in our ensemble were:
- Several U-Net with ResNet34 encoder and Squeeze-and-Excitation blocks - which helps the neural network add weights to the channel information. Better explained here.
- Several U-Net with DenseNet121 encoder, with different snapshots at different training epochs
- Several U-Net with ResNet34 encoder
We had many elaborate post-processing methods
- Fitting a 2D Flat-top Gaussian which helps with pixels at the edges of a ship
- Assume predictions range from 0-1 and the center of the ship typically have the most confidence
- Turn this distribution (which has peaks and valleys) into a nice flat plateau, which “averages” the confidences of the prediction
- Fitting rough bounding boxes around ships
- Dilating the predicted shapes of the ships of a certain size from the centroid
I explored different ideas the team had on where our models were coming up short and what we can do to improve our score. We used a shared local validation data set to ensure consistency across many experiments.
Results
Our models did great with ships that were 15k pixels or larger but struggled significantly with ships less than 50 pixels in size. Below table was calculated using our validation set.
| F2 score | F2 score | F2 score | F2 score | F2 score | |
|---|---|---|---|---|---|
| Models | <50px | <250px | <1500px | <15000px | 15000px+ |
| UDnet121_1_10_val | 0.002059236 | 0.050593745 | 0.11293854 | 0.3343008 | 0.2569069 |
| UDnet121d_1_12_val | 0.001147725 | 0.054444548 | 0.12659854 | 0.39598426 | 0.3392361 |
| Unet34SE_1_768_4c3_val | 0.002635205 | 0.04738022 | 0.14287518 | 0.4467376 | 0.35921985 |
| Unet34SE_2_768_8c1_val | 0.003423448 | 0.058901317 | 0.15762602 | 0.4724422 | 0.4091954 |
| Unet34_1_7_val | 0.00235253 | 0.027777225 | 0.077763714 | 0.35090417 | 0.29983974 |
The scores of the 50px ships were disturbingly low due to the high number of false positives.
Visualizing the results
Example of easy ship to detect, a long rectangle. The bounding box estimator (red rectangle) works well. The columns of images are results from the different U-Net models we trained.

But the bounding box estimator fails on small ships, because they look like blobs:

Not only did we have to predict where the ships were, we had to separate instances of ships, which can be difficult when they are docked together.

Public vs Private Leaderboard Shakeup
Kaggle often only displays scores evaluated on a subset of the test data as the Public Leaderboard. Once the competition completes, the winners are determined by the Private Leaderboard, which takes into account all of the test data.
In the final hours of the competition, our team placed 3rd in the public leaderboard with a pretty solid score to win gold. However when the private leaderboard was revealed, we dropped to 38th place. The submissions we had selected to be considered (with all the post processing) turned out to be worse than the submissions when we had done no post processing at all!
Lessons Learned
Neural network design / training:
- Use random crops to augment the dataset
- Especially useful for satellite data the training images are cropped regions of a bigger picture
- Supplement U-Net with MaskRCNN
About the validation vs test set:
- There was some data leakage from our training to validation set, leading to overfitting
- Our post processing led us to aggressively optimize for the public leaderboard score instead of relying on a solid local cross validation set that is selectively picked
- Kagglers often user a k-fold cross validation to ensure their models are robust against new test data
Other Solutions
- 4th place solution by Oleg Yaroshevskyy
- Smart random crop
- 6th place solution by b.e.s.
- Jumped from 41st to 6th place
- Created 5 folds validation without a leak
- MaskRCNN solution by tkuanlun350
- Most other solutions were U-Nets
- 9th place solution by Bo
- Training on ships, background and separation between ships